在复现一些web的CVE时,多会用到python脚本进行辅助攻击和利用,其中利用追到的无非就是requets库了。
requests库
安装
使用pip install requests即可下载该库,使用import即可导入该库

在github上下载源码进行编译安装,执行以下命令:

2
python setup.py install
单一命令使用
现在使用易优CMS进行演示
requests.get函数可以用来发送来发送http请求,并返回得到的数据包(默认保存在text文件中)。

当然上述命令用于发送get请求,参数可以直接拼接到url中,但如果post请求,则因该使用request.post 函数
在网站的后台登录出有post传参用户名和密码:
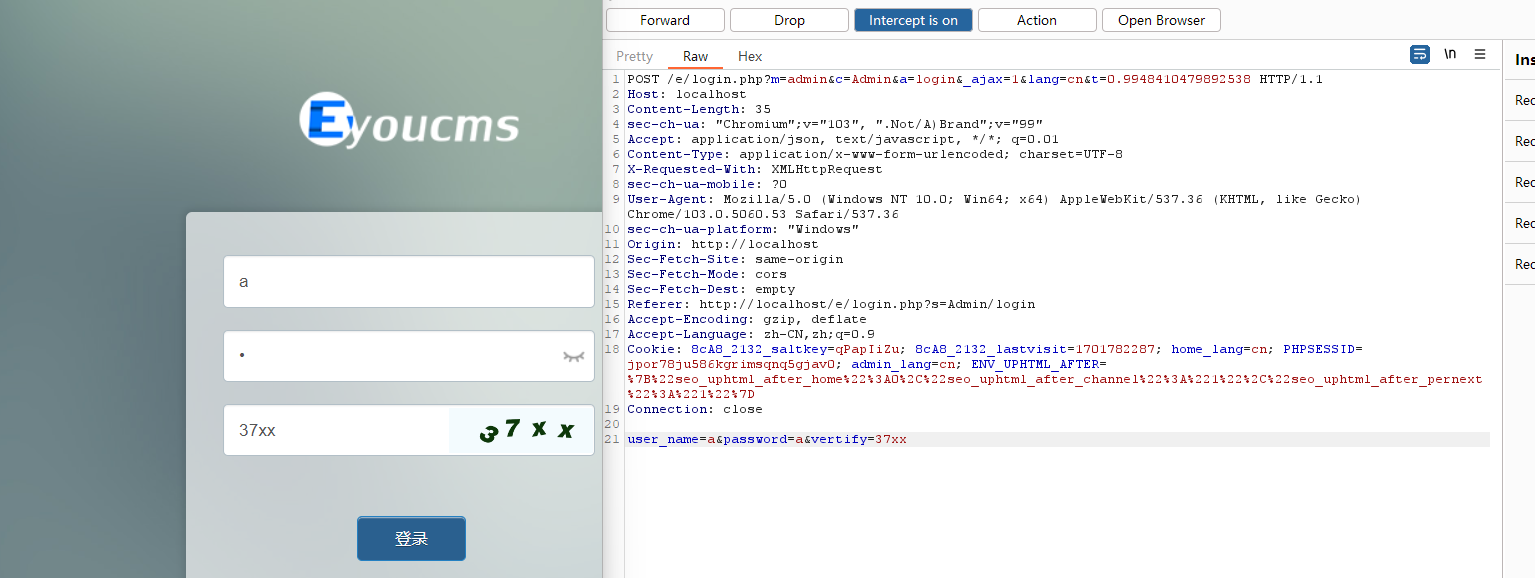
一般大多情况下post传参使用application/x-www-form-urlencoded格式,在requests中使用字典的格式被requests模块并传参。

当然reuquests还有PUT、DELETE等传参方式。
返回参数的利用
调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息,如状态码、响应头、响应内容等。
| 返回类型 | 解释(具体含义) |
|---|---|
| r.status_code | 获得http中返回的状态码,可用于编写一些网页状态的脚本(如文件上传-条件竞争) |
| r.url | 请求的最终地址(应是多见于30x的跳转 |
| r.encoding | 对于request返回的text文件的编码格式 |
| r.reason | 状态码的描述,例如404的Not Found 同r.status_code |
| r.content | 返回的相应内容,且为byte类型 |
| r.text | 对于request返回的text文件 |
| r.json | 内置得JSON解码器 |
| r.cookie | 返回得cookie值 |
ip伪造head头部伪造
当然一个网站有时会对请求会检测请求的浏览器类型,ip地址等,这是会涉及到head头部伪造
使用IP代理池伪装IP
利于python中定义自己想要设置得ip地址:
1 | import requests |
对于代理ip的获取,可以使用python爬取免费的且可爬取的代理ip例如在github上一个开源的代理IP地址**ProxyPool** ,通过如下代码获取代理IP
1 | import requests |
浏览器伪装
大多User-Agent值可以通过开发者工具(F12)获取到比如常见的:
1 | import requests |

对于一些网站对于访问速率(频次)的限制,可以使用一个time库中的sleep进行延迟发送,当然更加逼真的话可以使用random库中的random()函数来生成随机数进行变频访问
会话保持
大多数网站是通过session对象跨请求保持某些参数,即保持登陆状态,官方的说就是你使用requests尝试登录并且验证成功,服务端会返回一些Cookie,这些Cookie可以使你的下次请求不需要验证,而Session对象能保持这些Cookie,而不用你每次提交请求时构建一个新的Cookie。
例如使用rs = requests.Session() 来打开会话,在获取返回结果时用restult = session.post/get()。利用在登录一个post传参的网站时,可以使用如下代码:
1 | import requests |
文件上传和下载
对于一些CVE脚本会进行一些文件上传的操作(如上传一句木马),但这是并不是htnl代码般浏览器访问选择文件然后上传。以post方式(表单)上传多是先将二进制文件读取到内存中,再将内存中的文件发送到服务器保存。
单文件上传
例如下列代码:
1 | import requests |
多文件上传
多文件上传同于单文件上传,只需修改一下file参数即可:
1 | files {('file1',('shell1.php'open('shell1.php','rb'),'image/png')) |
其实还有以流的方式上传和监听时上传(requests-toolbet),但还未学习。
文件下载
对于较小文件可以直接利用写的操作完成:
1 | import requests |
当 Python 写入文件时,会将数据暂存在内存中,直至缓存存满后才真正写入文件。如果需要写入的数据很大,可能会导致内存不足。因此对于大文件的下载,可以采取分块读写的方法,每次只读写一小块。
1 | import requests |
- 这里with会自动判断是否关闭文件,所以不用在写
f.close()函数了。但浏览一些网上文章显示后讲到会遇到文件关闭后在一直占用进程,可能与部署的应用和版本有关吧?
命令行传参
大多脚本都时在cmd/bash下进行命令行传参,这样方便管理和使用。在传参是多会用到if __name__ == "__main__":函数
python属于脚本语言,同于php语言,对代码是逐句解释运行,一直从首行运行到尾行,这样会出现一些函数需要在特定条件下执行而无法被提前或滞后执行。而if __name__ == "__main__":可以作为程序入口进行选择性执行一些函数。但它与C语言中的mian()不同的是可以多个文件中出现。
对于cmd中的参数,会使用到sys库中的argv,但要注意到是argv本身为一个数组,接受的一个了参数(argv[0])是文件本身的名称,因此cmd下执行时第一个参数接受代码应为:sys.argv[1]
例如以前的在upload-lab中条件竞争模块使用的脚本:
1 | ## shell.py |
例如执行python shell.py -u http://127.0.0.1/xxx/shell.php 执行后 url等于“ http://127.0.0.1/xxx/shell.php”。
关于其他脚本的学习(类,函数定义,列表,库等)学习后单独更新。